
A Unified Namespace (UNS) is a central data structure where systems across the enterprise publish and subscribe to information in real time. Typically built on lightweight, event-driven technologies like MQTT and Sparkplug, the UNS enables decoupled communication between systems like PLCs, SCADA, historians, cloud services, and business applications.
What sets the UNS apart isn’t just connectivity, but consistency. Instead of mapping data from one system to another, each device or service speaks the same language, organized by a shared topic hierarchy. It provides live visibility, enhances responsiveness, and supports automation across platforms.
As powerful as the UNS is, most implementations stop short of their full potential. They’re rich in machine data, but often lack the context needed to understand why things happen, how well a process performed, or what the outcome was.
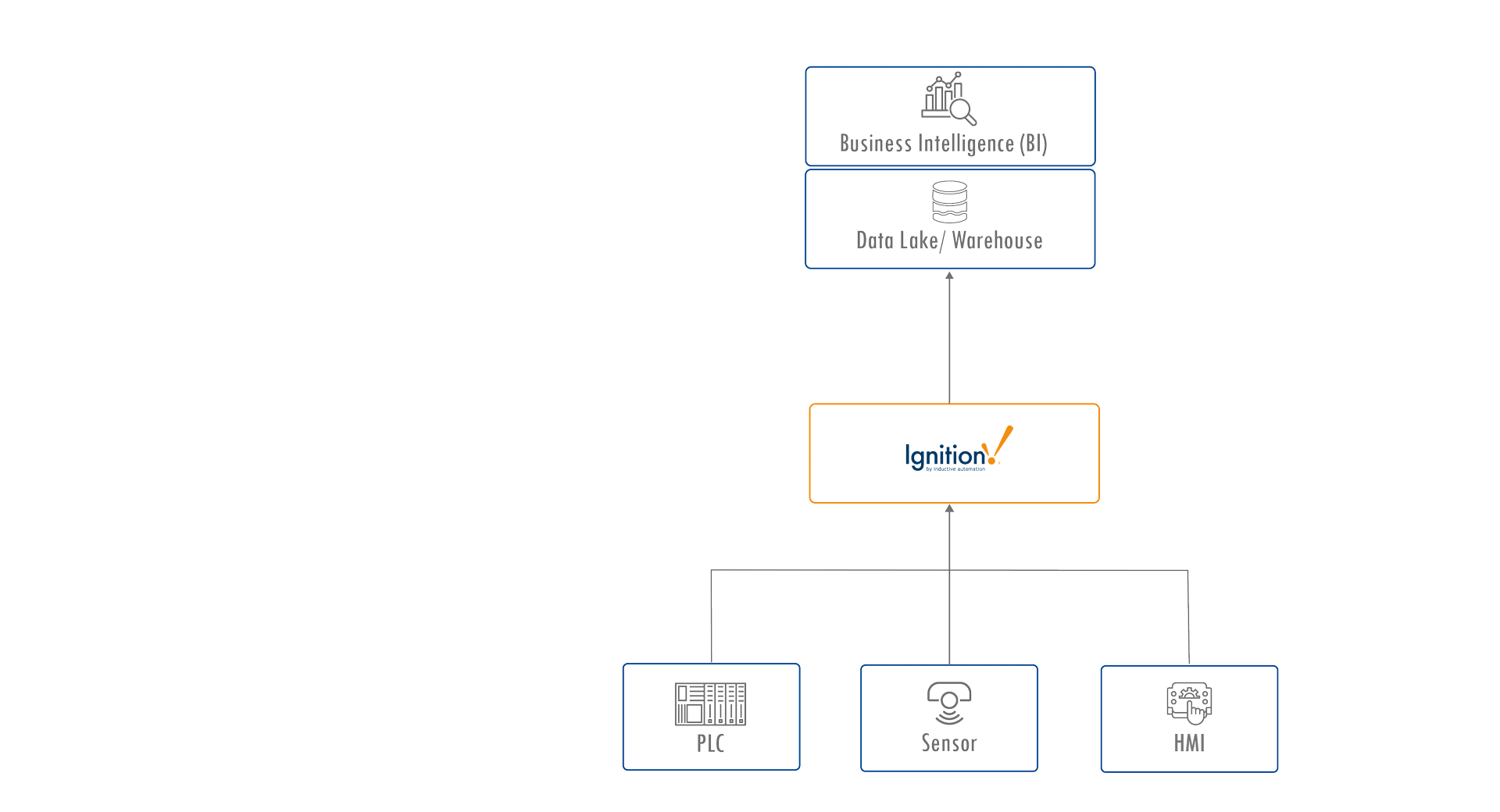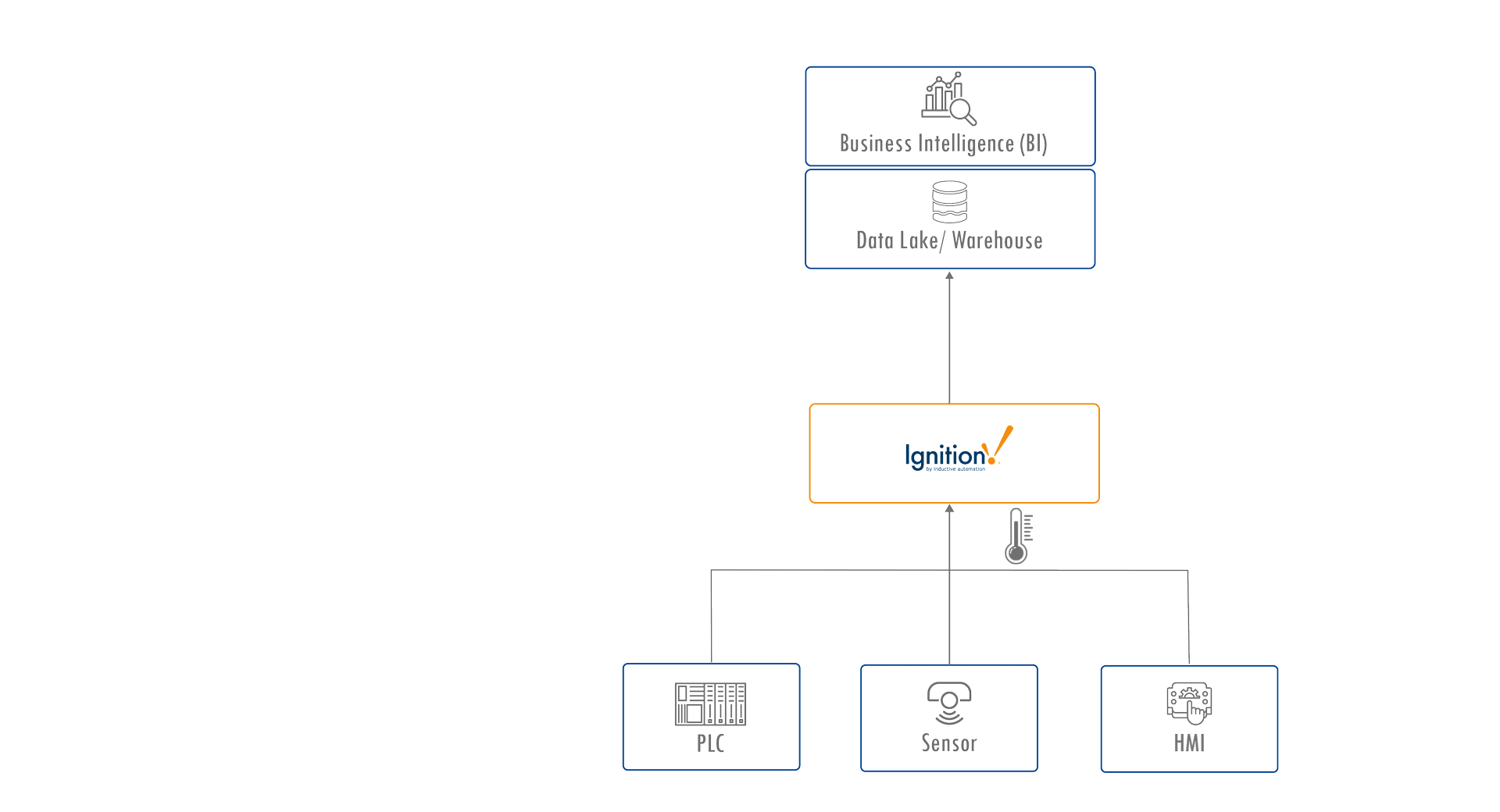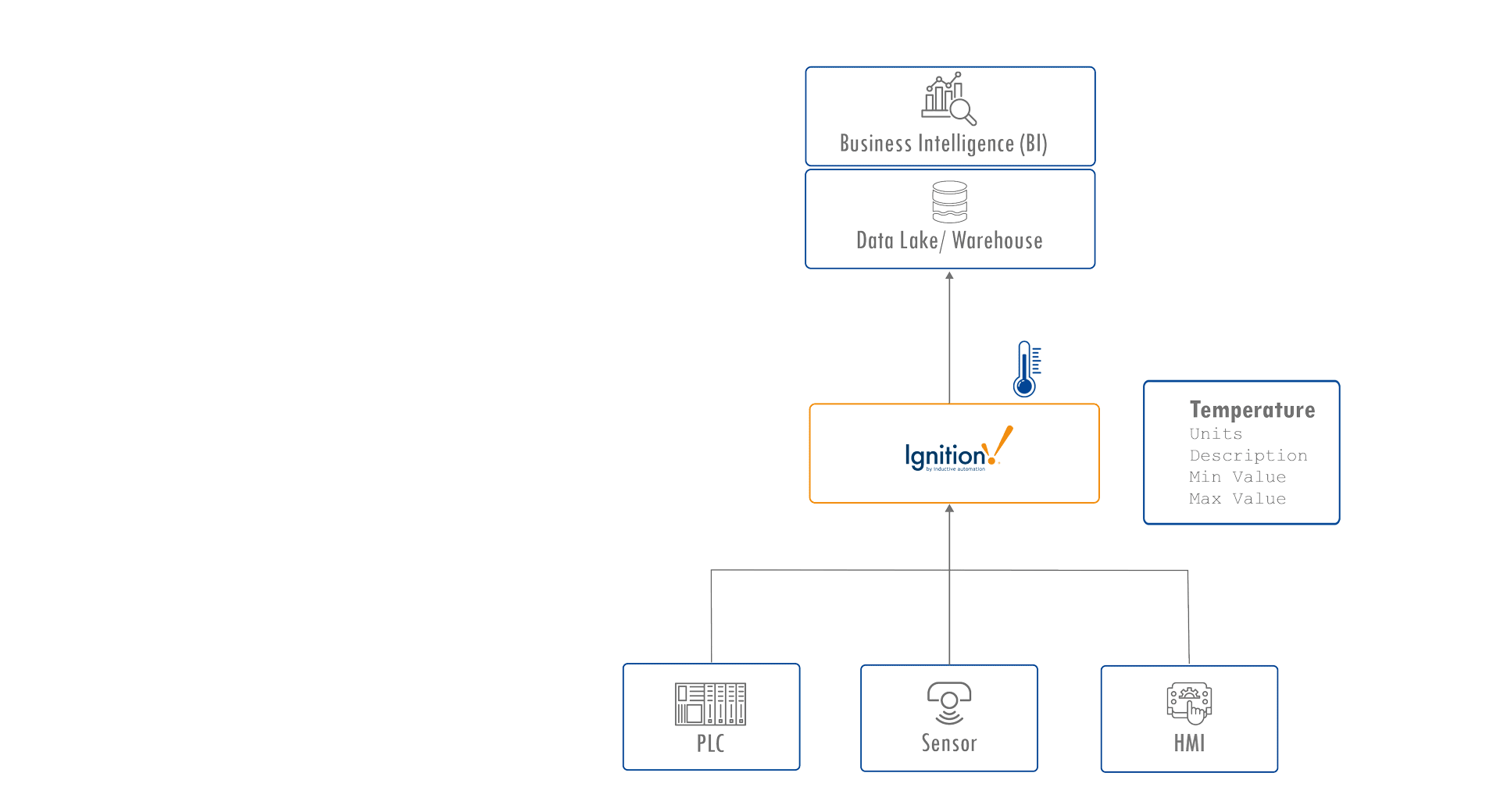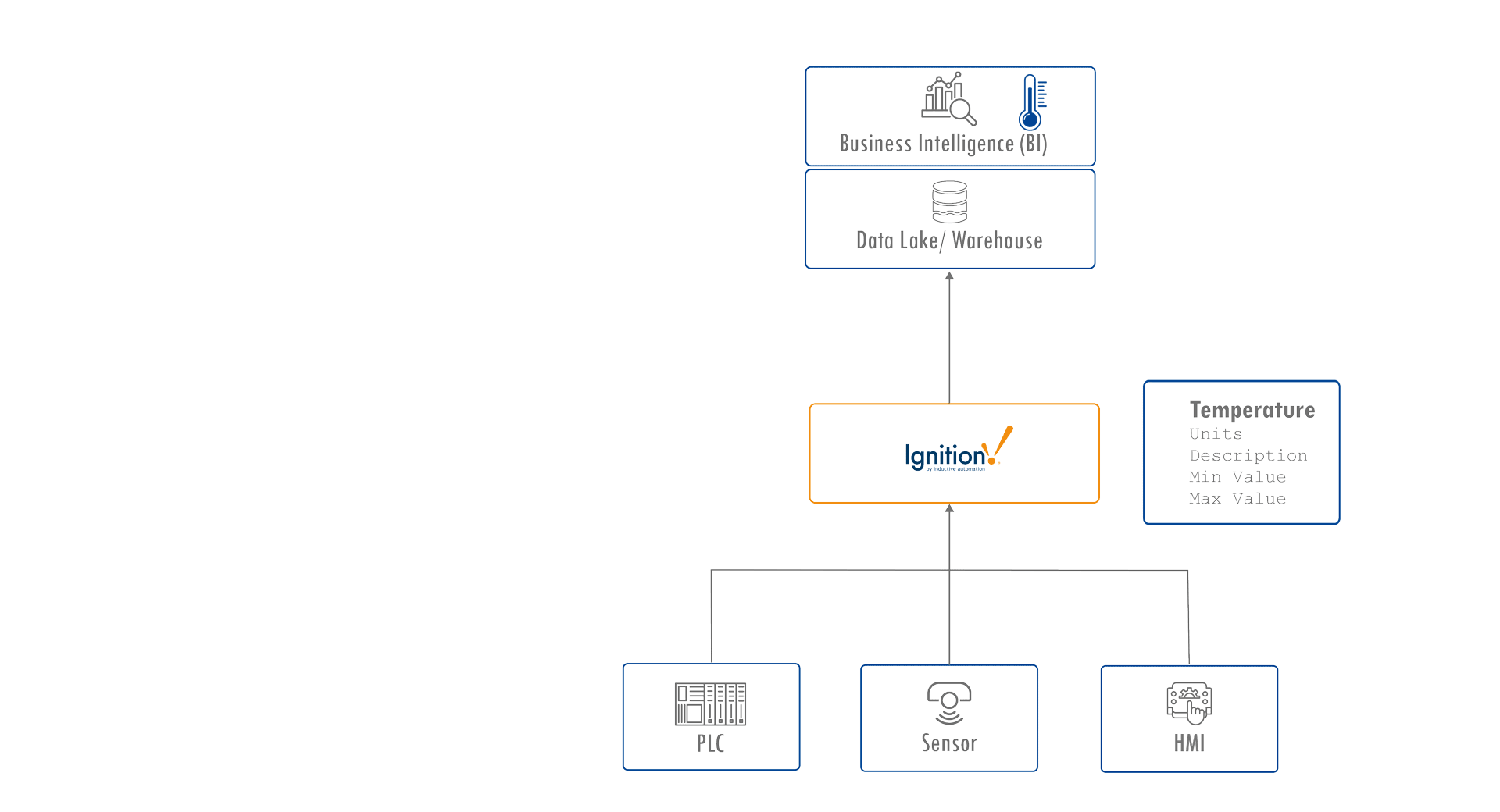
The Typical UNS Data Flow
Most UNS implementations focus on machine-layer data such as equipment status, sensor readings, setpoints, and control outputs. This data is ideal for answering immediate operational questions, such as whether a machine is running, if a fault is active, or how many units have been produced today, but it does not tell the full story behind those events.
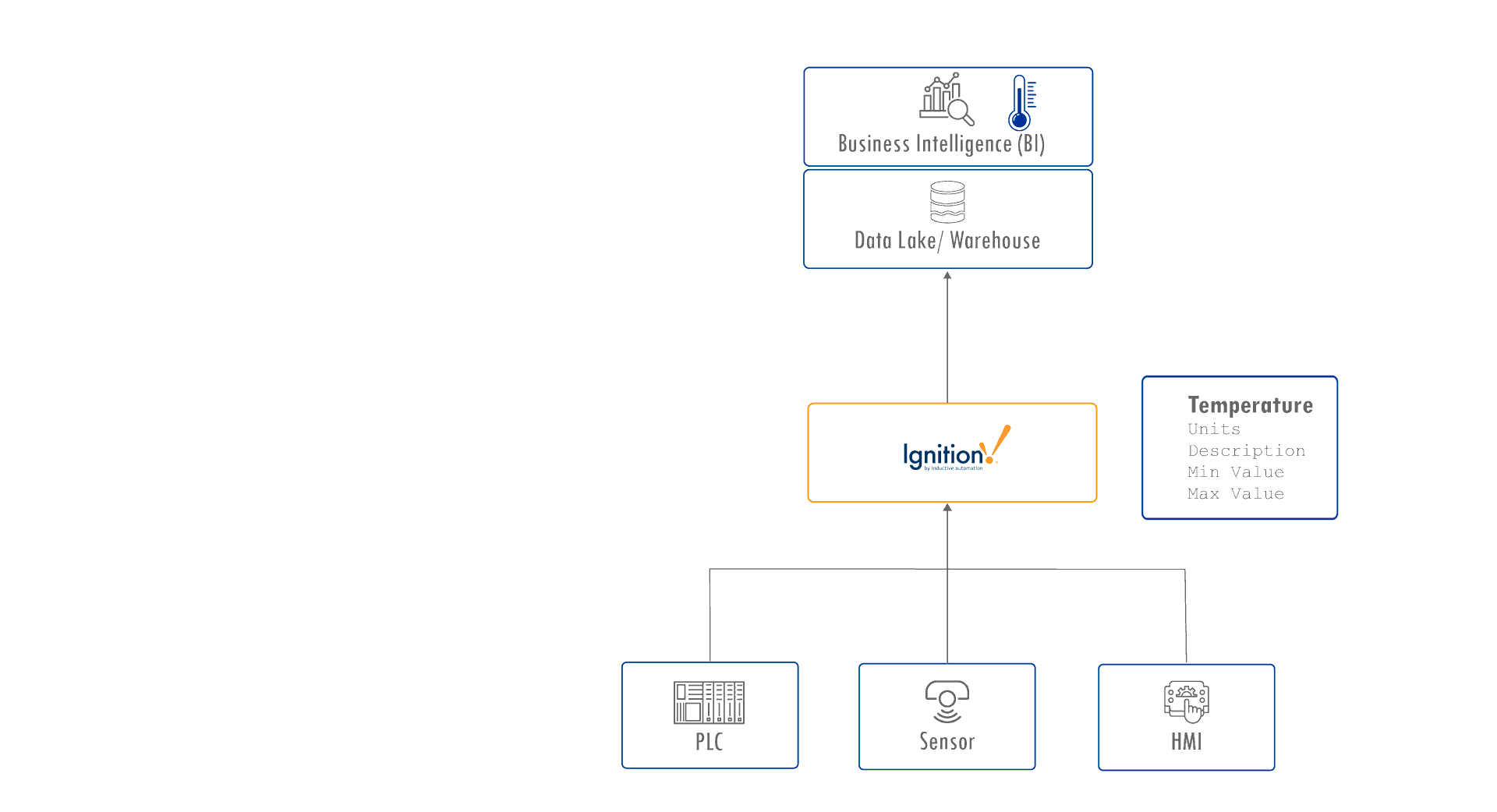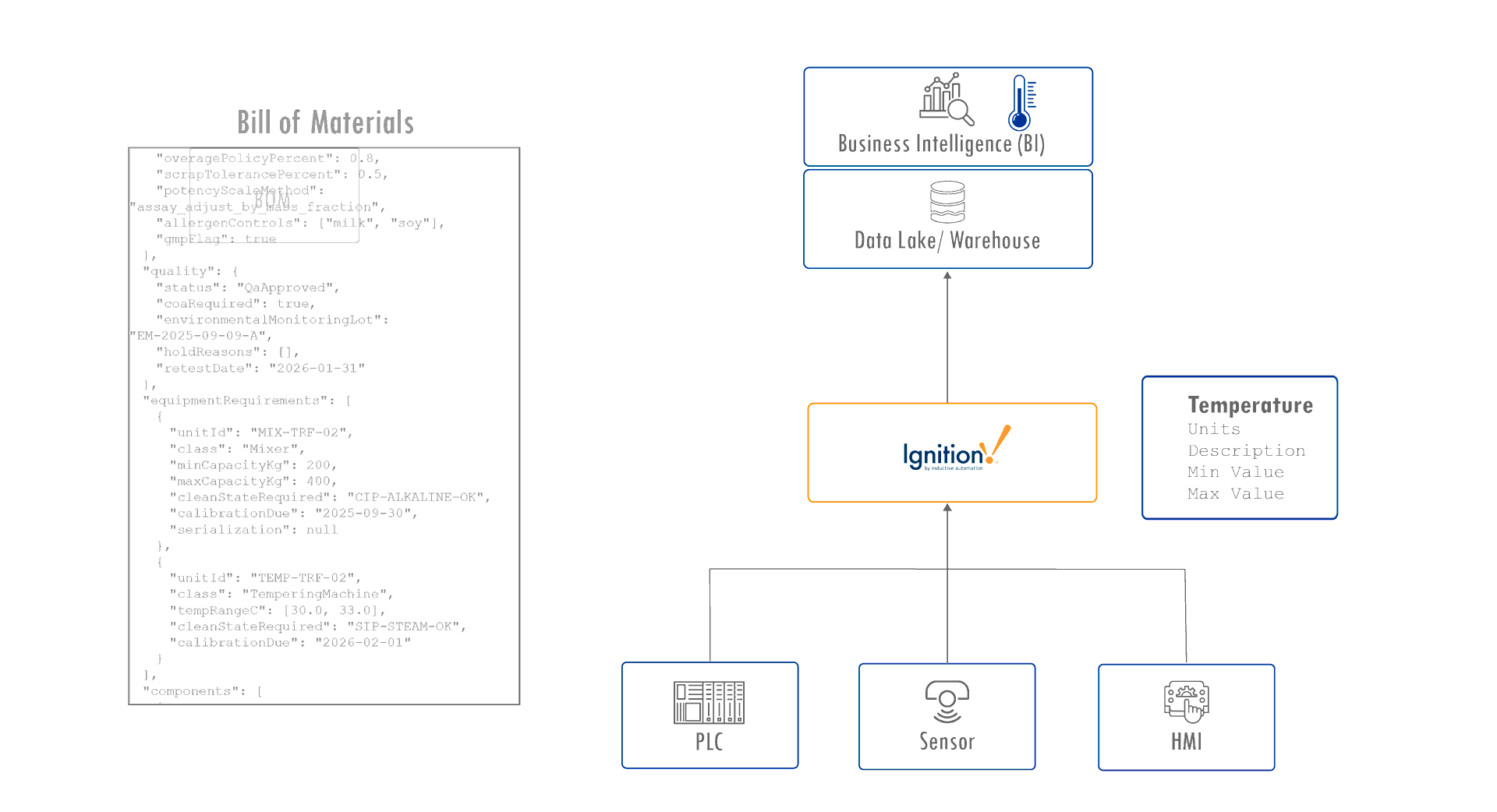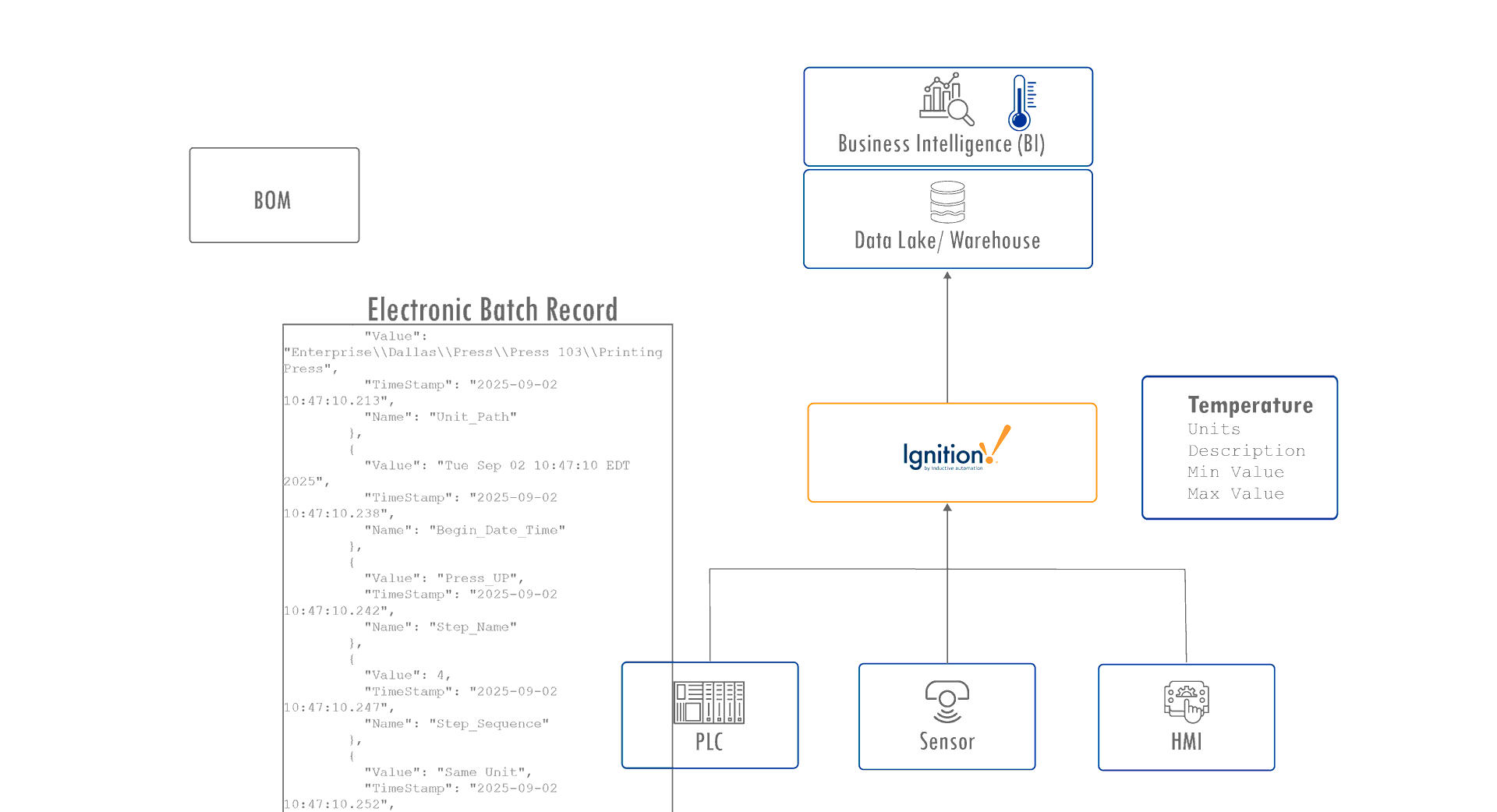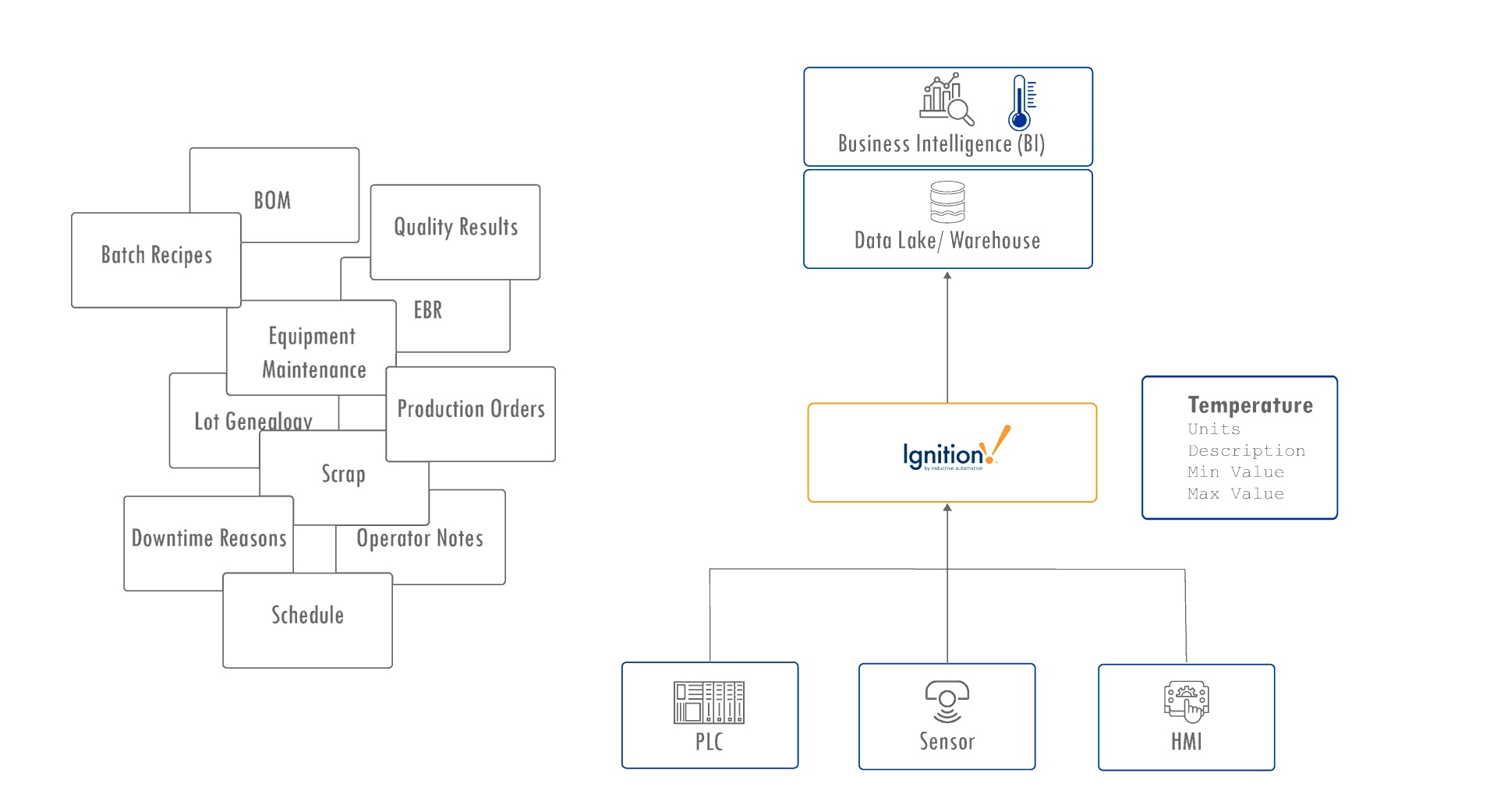
In many Unified Namespace architectures, platforms like Ignition by Inductive Automation serve as industrial data hubs, connecting control systems to enterprise systems such as data lakes and business intelligence tools. You might see a tag like Temperature = 22°C with associated properties such as units, min/max values, or a brief description.
![]()
When the Model Breaks Down
Now imagine trying to represent a Bill of Materials (BOM) in that same structure. A BOM is not a single tag but a collection of interrelated components and requirements. A UNS tends to support a fixed dependency structure, but a BOM requires a dynamic structure. Each BOM can have a different arrangement of dependent equipment, material, quality standards, specification, and constraints.
As soon as you introduce multi-dimensional MES data, the fixed nature of the typical UNS starts to struggle. Each record carries context that cannot be captured in a simple key-value pair. A batch might reference multiple lots, each with its own genealogy, yield, and environmental conditions. Tags alone cannot show those relationships.
This is where most UNS strategies stop short, not because the technology can’t handle it, but because the data coming from MES systems doesn’t fit the same simple structure. To move beyond this limitation, manufacturers need to understand what that missing context represents and how it turns raw data into something useful.
Why MES Context Matters
A Unified Namespace can tell you what is happening in real time, but not always why it is happening. Machine data shows what a sensor measured or when a fault occurred, but without MES context, it is difficult to understand what those signals mean for production, quality, or operations as a whole.
You might see that a mixer faulted at 2:56 p.m., but not what product was running or whether it was a planned stop. You might see a temperature reading of 205°F, but not whether it was within the recipe’s tolerance. The data is accurate, but incomplete.
That missing context lives in MES data. It connects each event to the products, people, and processes behind it:
- Batch recipes and production orders link materials, steps, and parameters.
- Quality results and electronic batch records (EBR) track compliance and outcomes.
- Downtime reasons and operator notes connect events to human insight.
- Equipment maintenance and lot genealogy show how assets and materials interact over time.
This is the kind of context that turns data into decisions. Bringing it into the same flow as machine data is what transforms a UNS from a communication layer into a true foundation for operational intelligence.
The Challenge and the Consequences
Even when manufacturers recognize the value of MES context, getting that information into a Unified Namespace is rarely straightforward. In many cases, MES data never makes it into the UNS at all. As a result, analytics and AI projects often remain limited to equipment-level insights. Teams can see what happened on a line, but not why it happened or how production context influenced the outcome.
To fill these gaps, manufacturers take a variety of approaches. Some export MES records into spreadsheets or BI tools and rebuild context by hand. Others write one-off scripts to push specific MES transactions into the UNS or a data lake. Many try to stitch machine and MES data together downstream by aligning timestamps or joining tables after the fact.
These methods can work in isolated cases, but they are difficult to maintain and nearly impossible to scale. In practice, the same calculations often get performed on the plant floor and again in higher-level analytics or AI tools, which leads to inconsistent results and added maintenance effort. Most importantly, these workarounds rarely produce the clean, contextualized, real-time data required for meaningful analytics or AI.
Extending the UNS
A more sustainable approach involves preparing MES data in a structured and contextualized form so that it is already organized, accurate, and ready for use within a Unified Namespace or any downstream system. In practice, this means:
- Define what data is needed: Identify the systems, fields, and formats required for analysis.
- Stream data from multiple sources: Bring in time-series, transactional, and production data from Ignition, MES, QMS, ERP, and other systems.
- Link and contextualize: Match each reading or event with the correct batch, product, step, equipment, or time window so the data actually has meaning.
- Prepare the dataset: Filter, group, and calculate the values needed for analysis, turning raw events into structured, analytics-ready information.
- Publish results: Send the processed data to Ignition, BI tools, AI models, or data warehouses in the exact format they expect.
The result is what you might think of as an Extended Unified Namespace (XUNS), a namespace that carries both real-time machine data and the production context that explains it.
The video below shows an example of what that transformation could look like in practice using Sepasoft’s SepaIQ Platform. On the left, the UNS presents raw tag readings that are accurate but fragmented. On the right, the Extended UNS (XUNS) has grouped and calculated those readings into batch-level consumption data that tells a clear production story.
How Sepasoft Can Help
Sepasoft designed SepaIQ as an MES analytics and data preparation layer that seamlessly extends the Unified Namespace. Instead of maintaining one-off scripts or rebuilding context by hand, teams can rely on SepaIQ to streamline data preparation from ingestion and linking through transformation and publication.
The result is an enterprise-ready foundation for analytics, AI, and continuous improvement, built on clean, contextualized, and connected data. To learn more, schedule a demo with our team of experts.